Partitions#
Dagster provides the Partition Set abstraction for pipelines where each run deals with a subset of data.
Relevant APIs#
| Name | Description |
|---|---|
PartitionSetDefinition | The class to define a partition set. |
Overview#
Partition sets let you define a set of logical "partitions", usually time windows, along with a scheme for building pipeline run config for a partition. Having defined a partition set, you can kick off a pipeline run or set of pipeline runs by simply selecting partitions in the set.
Partitions have two main uses:
- Partitioned Schedules: You can construct a schedule that targets a single partition for each run it launches. For example, a pipeline might run each day and process the data that arrived during the previous day.
- Backfills: You can launch a set of pipeline runs all at once, each run targeting one of the partitions in the set. For example, after making a code change, you might want to re-run your pipeline on every date that it has run on in the past.
Defining a Partition Set#
Here's a pipeline that computes some data for a given date.
@solid(config_schema={"date": str})
def process_data_for_date(context):
date = context.solid_config["date"]
context.log.info(f"processing data for {date}")
@solid
def post_slack_message(context):
context.log.info("posting slack message")
@pipeline
def my_data_pipeline():
process_data_for_date()
post_slack_message()
The solid process_data_for_date takes, as config, a string date. This piece of config will
define which date to compute data for. For example, if we wanted to compute for May 5th, 2020,
we would execute the pipeline with the following config:
solids:
process_data_for_date:
config:
date: "2020-05-05"
You can define a PartitionSetDefinition that defines the full set of
partitions and how to define the run config for a given partition.
def get_date_partitions():
"""Every day in the month of May, 2020"""
return [Partition(f"2020-05-{str(day).zfill(2)}") for day in range(1, 32)]
def run_config_for_date_partition(partition):
date = partition.value
return {"solids": {"process_data_for_date": {"config": {"date": date}}}}
date_partition_set = PartitionSetDefinition(
name="date_partition_set",
pipeline_name="my_data_pipeline",
partition_fn=get_date_partitions,
run_config_fn_for_partition=run_config_for_date_partition,
)
Partitions in Dagit#
The Partitions Tab#
In Dagit, you can view runs by partition in the Partitions tab of a Pipeline page.
In the "Run Matrix", each column corresponds to one of the partitions in the partition set. Each row corresponds to one of the steps in the pipeline.
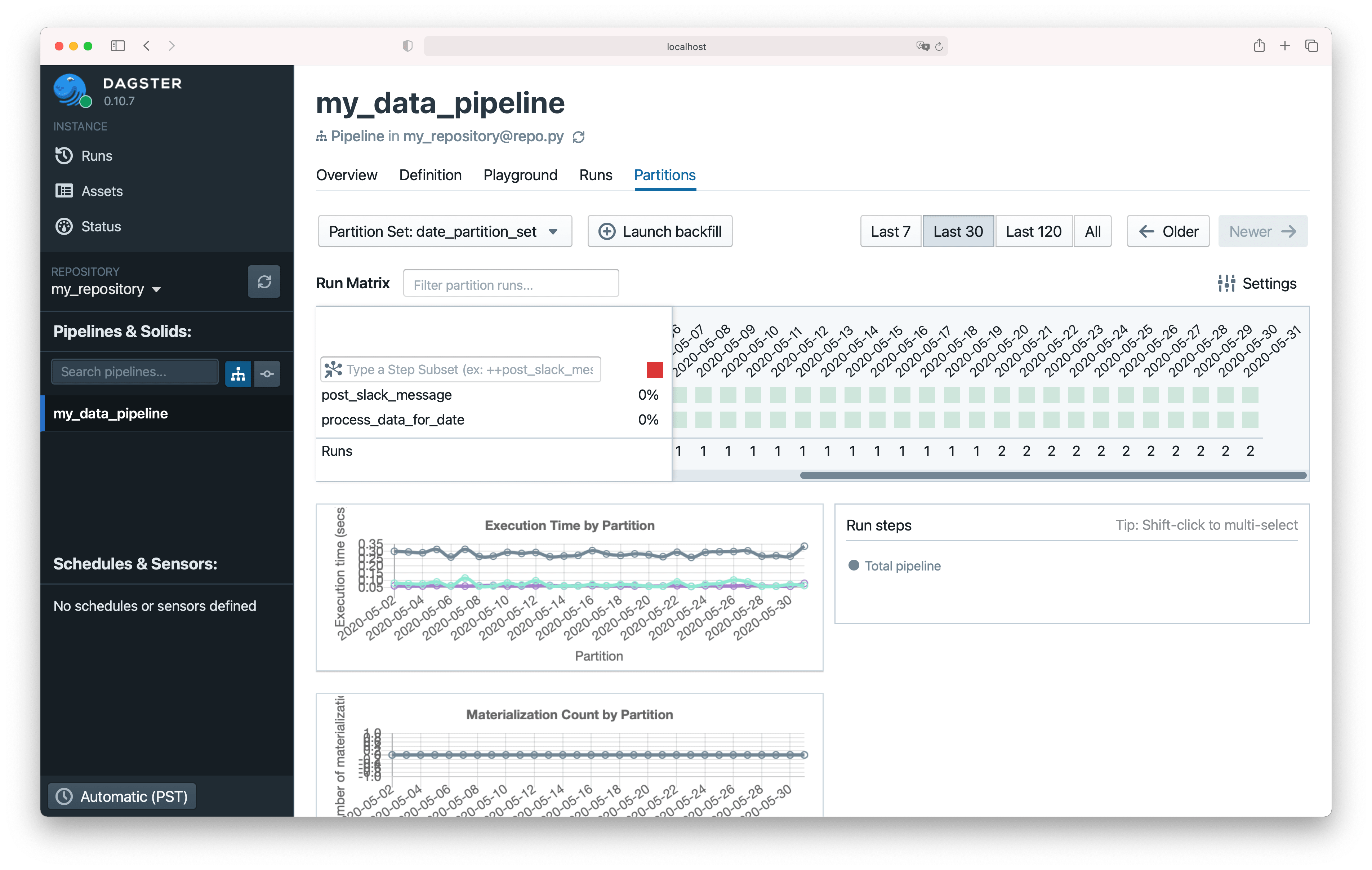
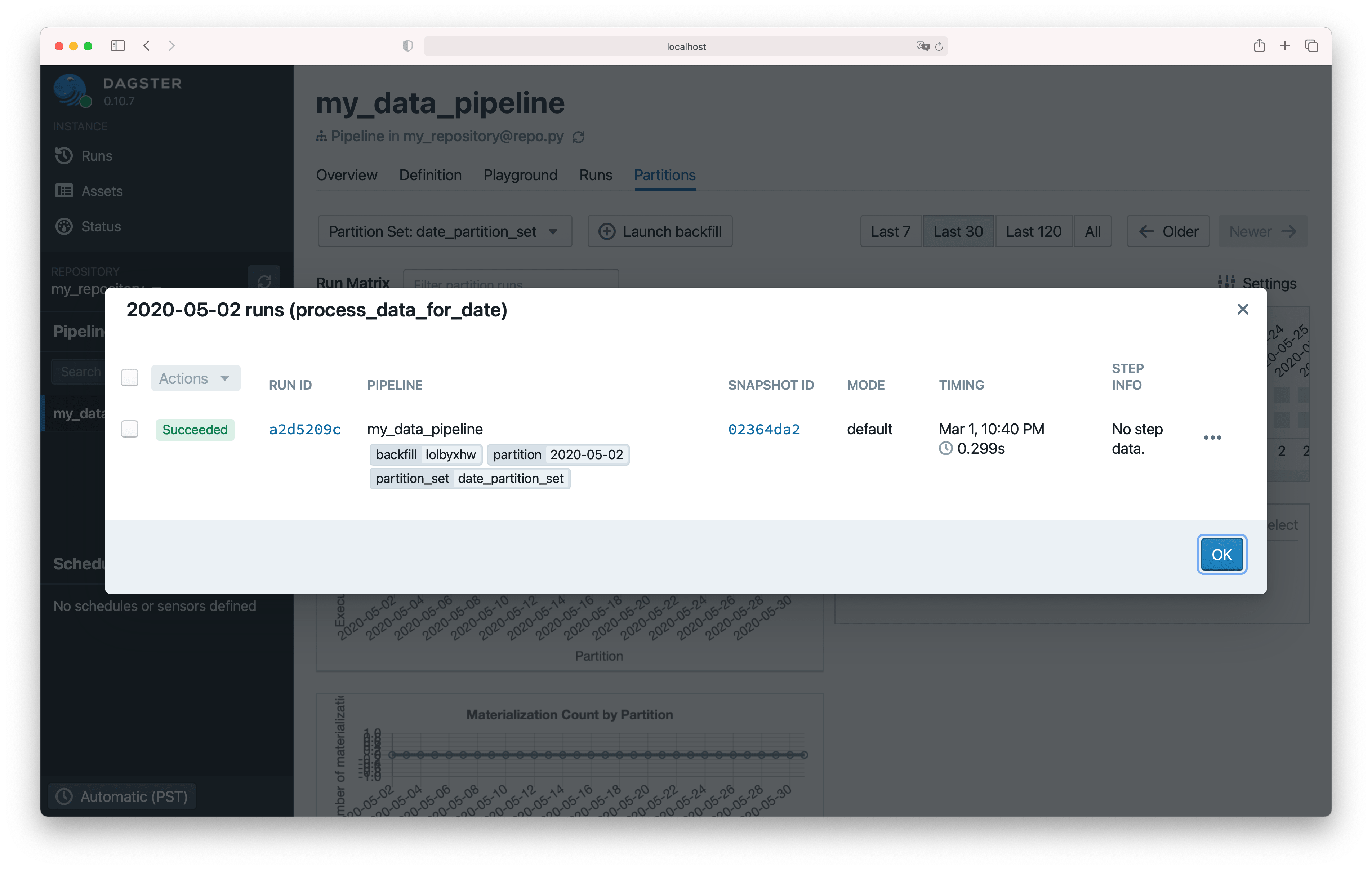
You can click on individual boxes to see the history of runs for that step and partition.
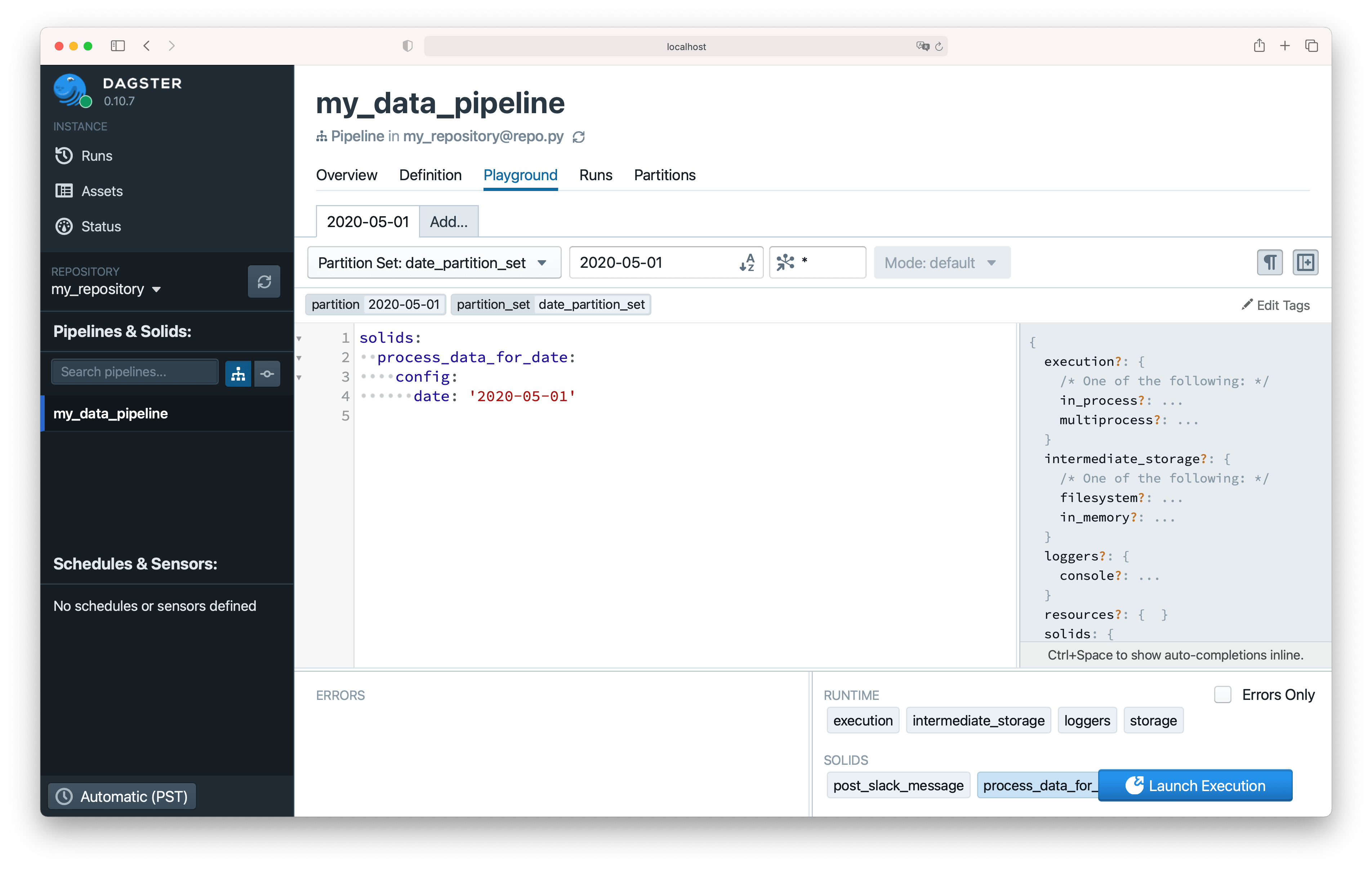
Launching Partitioned Runs from the Playground#
You can view and use partitions in the Dagit playground view for a pipeline. In the top bar, you can select from the list of all available partition sets, then choose a specific partition. Within the config editor, the config for the selected partition will be populated.
In the screenshot below, we select the date_partition_set and the 2020-05-01 partition, and we can see that
the correct run config for the partition has been populated in the editor.