Asset Materializations#
"Asset" is Dagster's word for an entity, external to solids, that is mutated or created by a solid. An asset might be a table in a database that a solid appends to, an ML model in a model store that a solid overwrites, or even a slack channel that a solid writes messages to.
Solid outputs often correspond to assets. For example, a solid might be responsible for recreating a table, and one of its outputs might be a dataframe containing the contents of that table.
Assets can also have partitions, which refer to slices of the overall asset. The simplest example would be a table that has a partition for each day. A given solid execution may simply write a single day's worth of data to that table, rather than dropping the entire table and replacing it with new data.
Dagster lets you track the interactions between solids, outputs, and assets over time and view them in the Dagit Asset Catalog. Every asset has a "key", which serves as a unique identifier for that particular entity. The act of creating or updating the contents of an asset is called a "materialization", and Dagster tracks these materializations using AssetMaterialization events. These events can either be yielded by the user at runtime, or automatically created by Dagster in cases where an AssetKey has been referenced by a solid output.
Relevant APIs#
| Name | Description |
|---|---|
AssetMaterialization | Dagster event indicating that a solid has materialized an asset. |
AssetKey | A unique identifier for a particular external asset |
Overview#
There are two general patterns for dealing with assets when using Dagster:
- Put the logic to write/store assets inside the body of a solid.
- Focus the solid purely on business logic, and delegate the logic to write/store assets to an IOManager.
Regardless of which pattern you are using, AssetMaterialization events are used to communicate to Dagster that a materialization has occurred. You can create these events either by explicitly yielding them at runtime, or (using an experimental interface), have Dagster automatically generate them by defining that a given solid output corresponds to a given AssetKey.
Explicit AssetMaterializations#
One way of recording materialization events is to explicitly yield AssetMaterialization events at runtime. These events should be co-located with your materialization logic, meaning if you store your object within your solid body, then you should yield from within that solid, and if you store your object using an IOManager, then you should yield the event from your manager.
Yielding an AssetMaterialization from a Solid#
To make Dagster aware that we materialized an asset in our solid, we can yield an AssetMaterialization event. This would involve changing the following solid:
@solid
def my_simple_solid(_):
df = read_df()
remote_storage_path = persist_to_storage(df)
return remote_storage_path
into something like this:
@solid
def my_materialization_solid(context):
df = read_df()
remote_storage_path = persist_to_storage(df)
yield AssetMaterialization(asset_key="my_dataset", description="Persisted result to storage")
yield Output(remote_storage_path)
Note: Our materialization solid must now explicitly yield an Output event instead of relying on the implicit conversion of the return value into an Output event.
We should now see a materialization event in the event log when we execute this solid.
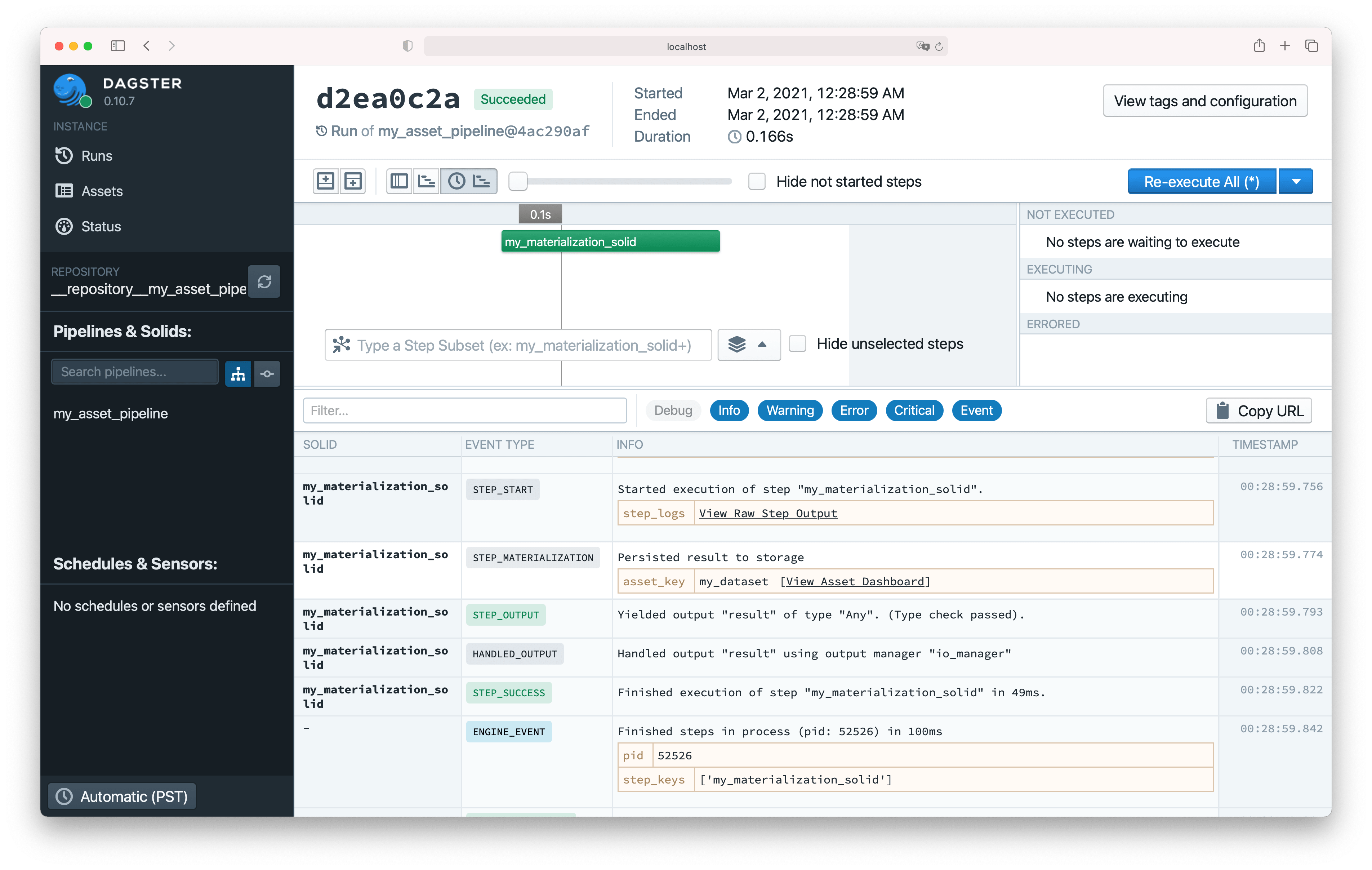
Yielding an AssetMaterialization from an IOManager#
To record that an IOManager has mutated or created an asset, we can yield an AssetMaterialization event from its handle_output method.
class PandasCsvIOManager(IOManager):
def load_input(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return read_csv(file_path)
def handle_output(self, context, obj):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
obj.to_csv(file_path)
yield AssetMaterialization(
asset_key=AssetKey(file_path), description="Persisted result to storage."
)
Attaching Metadata to an AssetMaterialization#
There are a variety of types of metadata that can be associated with a materialization event, all through the EventMetadataEntry class. Each materialization event optionally takes a list of metadata entries that are then displayed in the event log and the Asset Catalog.
Example: Solid body#
@solid
def my_metadata_materialization_solid(context):
df = read_df()
remote_storage_path = persist_to_storage(df)
yield AssetMaterialization(
asset_key="my_dataset",
description="Persisted result to storage",
metadata_entries=[
EventMetadataEntry.text("Text-based metadata for this event", label="text_metadata"),
EventMetadataEntry.fspath(remote_storage_path),
EventMetadataEntry.url("http://mycoolsite.com/url_for_my_data", label="dashboard_url"),
EventMetadataEntry.float(calculate_bytes(df), "size (bytes)"),
],
)
yield Output(remote_storage_path)
Example: IOManager#
class PandasCsvIOManagerWithAsset(IOManager):
def load_input(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return read_csv(file_path)
def handle_output(self, context, obj):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
obj.to_csv(file_path)
yield AssetMaterialization(
asset_key=AssetKey(file_path),
description="Persisted result to storage.",
metadata_entries=[
EventMetadataEntry.int(obj.shape[0], label="number of rows"),
EventMetadataEntry.float(obj["some_column"].mean(), "some_column mean"),
],
)
Check our API docs for EventMetadataEntry for more details
on they types of event metadata available.
Specifying a partition for an AssetMaterialization#
If you are materializing a single slice of an asset (e.g. a single day's worth of data on a larger table), rather than mutating or creating it entirely, you can indicate this to Dagster by including the partition argument on the object.
@solid(config_schema={"date": str})
def my_partitioned_asset_solid(context):
partition_date = context.solid_config["date"]
df = read_df_for_date(partition_date)
remote_storage_path = persist_to_storage(df)
yield AssetMaterialization(asset_key="my_dataset", partition=partition_date)
yield Output(remote_storage_path)
Linking Solid Outputs to Assets Experimental#
It is fairly common for an asset to correspond to a solid output. In the following simplified example, our solid produces a dataframe, persists it to storage, and then passes the dataframe along as an output:
@solid
def my_asset_solid(context):
df = read_df()
persist_to_storage(df)
yield AssetMaterialization(asset_key="my_dataset")
yield Output(df)
In this case, the AssetMaterialization and the Output events both correspond to the same data, the dataframe that we have created. With this in mind, we can simplify the above code, and provide useful information to the Dagster framework, by making this link between the my_dataset asset and the output of this solid explicit.
Just as there are two places in which you can yield runtime AssetMaterialization events (within a solid body and within an IOManager), we provide two different interfaces for linking a solid output to to an asset. Regardless of which you choose, every time the solid runs and yields that output, an AssetMaterialization event will automatically be created to record this information.
If you specified any metadata entries on the Output event while yielding it (see: Solid Event Docs),
these entries will automatically be attached to the materialization event for this asset.
Linking assets to an Output Definition Experimental#
For cases where you are storing your asset within the body of a solid, the easiest way of linking an asset to a solid output is with the asset_key parameter on the relevant OutputDefinition in your solid.
This parameter can be one of two things. For simple cases, where a solid will always be writing to the same asset, you can define a constant AssetKey that identifies the asset you are linking.
@solid(output_defs=[OutputDefinition(asset_key=AssetKey("my_dataset"))])
def my_constant_asset_solid(context):
df = read_df()
persist_to_storage(df)
yield Output(df)
For cases where the asset that you want to link to an output might change based on some context in
the pipeline (such as the mode), you can pass in a function that takes OutputContext and returns
an AssetKey.
def get_asset_key(context: OutputContext):
mode = context.step_context.mode_def.name
return AssetKey(f"my_dataset_{mode}")
@solid(output_defs=[OutputDefinition(asset_key=get_asset_key)])
def my_variable_asset_solid(context):
df = read_df()
persist_to_storage(df)
yield Output(df)
Linking assets to outputs with an IOManager Experimental#
If you've defined a custom IOManager to handle storing your solid's outputs, the IOManager will likely be the most natural place to define which asset a particular output will be written to. To do this,
you can implement the get_output_asset_key function on your IOManager.
Similar to the above interface, this function takes an OutputContext and returns
an AssetKey. The following example functions nearly identically to PandasCsvIOManagerWithMetadata from the runtime example above.
class PandasCsvIOManagerWithOutputAsset(IOManager):
def load_input(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return read_csv(file_path)
def handle_output(self, context, obj):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
obj.to_csv(file_path)
yield EventMetadataEntry.int(obj.shape[0], label="number of rows")
yield EventMetadataEntry.float(obj["some_column"].mean(), "some_column mean")
def get_output_asset_key(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return AssetKey(file_path)
When an output is linked to an asset in this way, the generated AssetMaterialization event will contain any EventMetadataEntry information yielded from the handle_output function (in addiition to all of the metadata_entries specified on the corresponding Output event).
See the IOManager docs for more information on yielding these entries from an IOManager.
Specifying partitions for an output-linked asset#
If you are already specifying a get_output_asset_key function on your IOManager, you can optionally specify a set of partitions that this manager will be updating or creating by also defining a get_output_asset_partitions function. If you do this, an AssetMaterialization will be created for each of the specified partitions. One useful pattern to pass this partition information (which will likely vary each run) to the manager, is to specify the set of partitions on the configuration of the output. You can do this by providing per-output configuration on the IOManager.
Then, you can calculate the asset partitions that a particular output will correspond to by reading this output configuration in get_output_asset_partitions:
class PandasCsvIOManagerWithOutputAssetPartitions(IOManager):
def load_input(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return read_csv(file_path)
def handle_output(self, context, obj):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
obj.to_csv(file_path)
yield EventMetadataEntry.int(obj.shape[0], label="number of rows")
yield EventMetadataEntry.float(obj["some_column"].mean(), "some_column mean")
def get_output_asset_key(self, context):
file_path = os.path.join("my_base_dir", context.step_key, context.name)
return AssetKey(file_path)
def get_output_asset_partitions(self, context):
return set(context.config["partitions"])
Asset Lineage Experimental#
When a solid output is linked to an AssetKey, Dagster can automatically generate lineage information that describes how this asset relates to other output-linked assets.
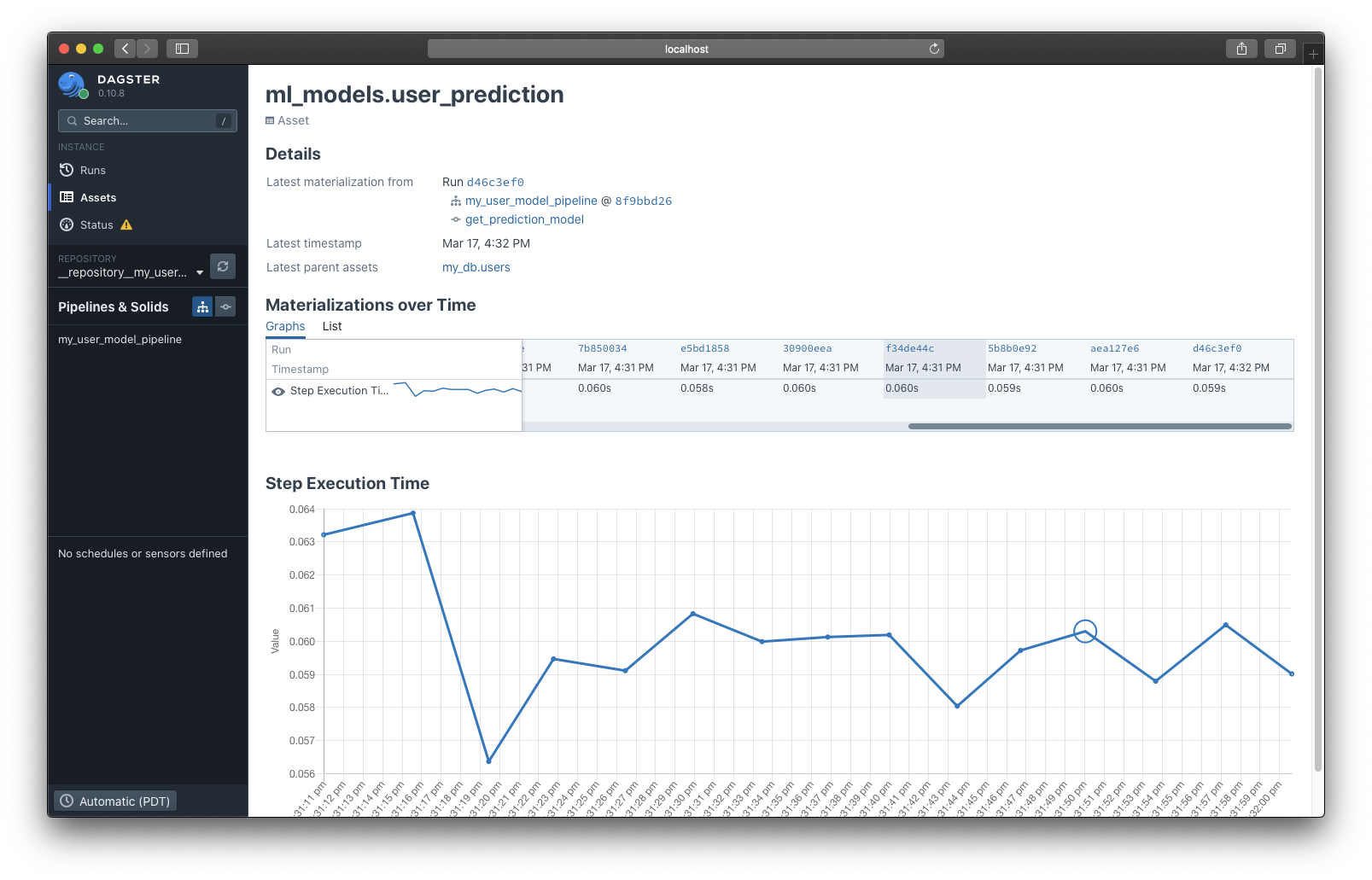
As a simplified example, imagine a two-solid pipeline that first scrapes some user data from an API, storing it to a table, then trains an ML model on that data, persisting it to a model store:
from dagster import solid, pipeline, OutputDefinition, AssetKey
@solid(output_defs=[OutputDefinition(asset_key=AssetKey("my_db.users"))])
def scrape_users(_):
users_df = some_api_call()
persist_to_db(users_df)
return users_df
@solid(output_defs=[OutputDefinition(asset_key=AssetKey("ml_models.user_prediction"))])
def get_prediction_model(_, users_df):
my_ml_model = train_prediction_model(users_df)
persist_to_model_store(my_ml_model)
return my_ml_model
@pipeline
def my_user_model_pipeline():
get_prediction_model(scrape_users())
In this case, it's certainly fair to say that this ML model, which we have assigned the key ml_models.user_prediction, depends on the table that we created, my_db.users (it uses the data in the table to train the model).
Why is that? By specifying the structure of your pipeline, you have already defined data depedencies between these solids. By linking the output of scrape_users to the input of get_prediction_model, we can now infer that whatever this second solid outputs will be some function of its input. Furthermore, since we have linked each of these outputs to external assets, we can use this knowledge to say that the asset associated with the output of get_prediction_model depends on the asset associated with the output of scrape_users.
This feature is still in its early stages, but for now, this lineage information is surfaced in the Asset Catalog page for each asset (Latest parent assets):